ECMAScript 2015 "Enhanced Object Literals" are an anti-pattern
This is an opinion.
Consider the following function written using the relatively new JavaScript feature of "Enhanced Object Literals".
// Authentication API requires a POST body in the form
// {"username": "string", "password", "string"}
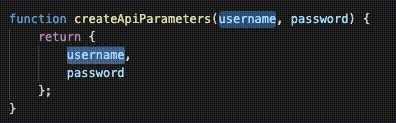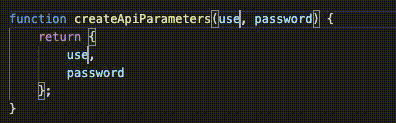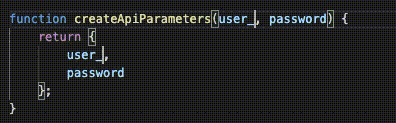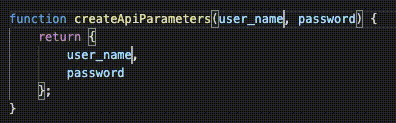
function createApiParameters(username, password) {
return {
username,
password
};
}
createApiParameters('david', '123');
// { username: 'david', password: '123' }Now, what would happen if we performed a refactor and changed our local variable of username to user_name. An application of The Principle of Least Astonishment tells us that changing the name of a function's argument should have zero effect on the output of that function.
createApiParameters('david', '123');
// { user_name: 'david', password: '123' }Oh no! Using this new syntax, we have assigned semantic meaning to the literal names of our variables, which in my opinion, is awful. Variable names should serve only as placeholders, not syntactic objects that also carry around metadata about their name.
Real Life™ examples are often more subtle than the one above. For example, your return statement might be 20 lines from your argument list, making the connection between the two invisible at first glance. For this reason, I will be sticking with the old syntax when creating dictionaries whose keys need to follow a strict contract.
return {
username: username,
password: password
};Side Note: The popular linting library ESLint do not currently have a rule to detect the usage of this language feature. I am considering creating an issue in their system for this.
Side Note': The Visual Studio Code editor, when performing a literal textual replacement reproduces the behavior described above. However, when using the built in refactor tool, it is smart enough to avoid changing the name of the object keys. However, my point still stands that a symbolic change to the source should not have a difference on output.